عنوان رساله: گسترش الگوریتم یادگیری تقویتی مبتنی بر مدل برای برنامهریزی دوسویه همپیوند با گرایش نزدیکشوندگی پاولفی
ارائه کننده: رضا کاکویی استاد راهنما: دکتر محمد تقی حمیدی بهشتی استاد مشاور اول: دکتر مهدی کرامتی استاد ناظر داخلی اول: دکتر وحید جوهری مجید استاد ناظر داخل دوم: دکتر مهدی سجودی استاد ناظر خارجی اول: دکتر بابک نجار اعرابی (دانشگاه تهران) استاد ناظر خارجی دوم: دکتر عبدالحسین وهابی (دانشگاه تهران) تاریخ: 1403/02/30 ساعت: 15 مکان: دانشکده مهندسی برق و کامپیوتر، بلوک 6، طبقه سوم، آزمایشگاه ابزار دقیق و اتوماسیون صنعتی، اتاق 38، گروه کنترل
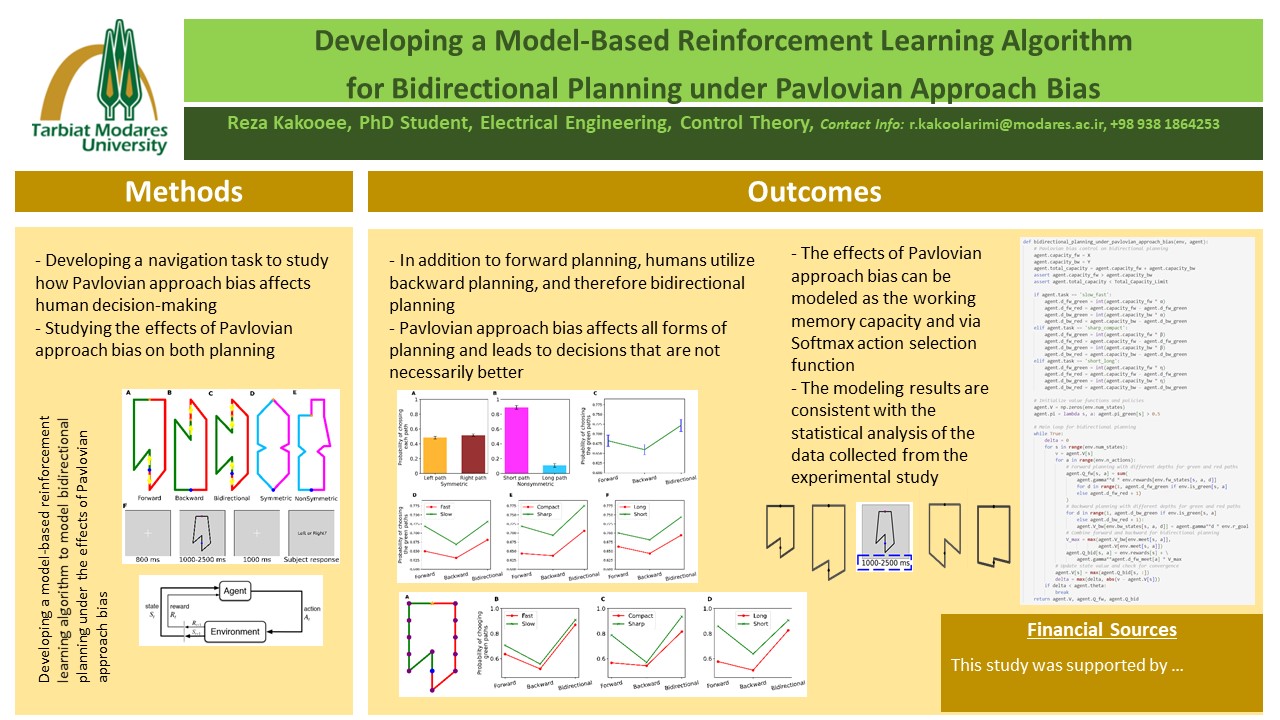
چکیده: شناسایی و مدلسازی سازوکارهای گوناگون مغز که فرآیندهای شناختی مانند تصمیمگیری را هدایت میکنند، دست کم از سه جنبهی مختلف حائز اهمیت فراوانی میباشد. نخست از دیدگاه علمی، شناسایی فرآیندهای شناختی راهی است به سوی کشف نادانستههایی در مورد مغز انسان؛ همان ارگان پیچیدهای که دنیای مدرن امروزی را خلق کرده است. دوم از دیدگاه پزشکی، درک سازوکارهای مغزی میتواند بابی به روی پاسخگویی به چالشهای متفاوتی باشد که امروزه پزشکان در مواجهه با بسیاری از بیماریهای مغزی با آن روبرو هستند. سوم از دیدگاه مهندسی است که خود از دو منظر میتواند درخور توجه باشد: اول، درک مناسبتر روابط و تعاملات بین اجزای گوناگون مغزی به منظور ارائه نظریههای ابتکاری در جهت تفسیر فرآیندهای مغزی، و دوم یاری رساندن به خود فضای مهندسی است. بدان معنا که مدلهای کشف شده شاید الهام بخش ابداع الگوریتمهایی گردند که در حل مسائل مهندسی کاراترند. در این بین شناسایی و مدلسازی سازوکارهای نهفته در پشت فرآیند تصمیمگیری، شایستهی توجه موشکافهای است. بدان جهت که تصمیمگیری نقش مهمی در جوانب گوناگون زندگی بازی میکند. پژوهشهای موجود نشان میدهند که تصمیمات در مغز در بستر دو سازوکار مجزا و در عین حال مرتبط به هم شکل میگیرند: یادگیری پاولفی و کنترل ابزاری. یادگیری پاولفی با آموختن پیوند محرک-پیامد به یادگیری منجر میشود بدون آنکه به عمل انتخابی وابسته باشد. همچنین پاسخهای غریزیای را بازنمایی میکند که در طول فرگشت در مغز ایجاد شده و بهوسیلهی ایماهای محیط هدایت میشوند. بهگونهای که انسانها گرایش به نزدیکشدن به محرکهای نوید دهندهی پاداش دارند در مقایسه با محرکهای خنثی، و محرکهایی که نشان از دریافت تنبیهی دارند. در طرف مقابل کنترل ابزاری نوعی فرآیند یادگیری است که با توجه به عملی که از تصمیمگیرنده سر زده، و بازخوردی که از طرف محیط در پاسخ به آن رفتار دریافت شده، موجب تقویت یا تضعیف احتمال بروز مجدد آن رفتار در آینده میگردد. این کنترلگر به ما میآموزد در هر شرایطی بهترین عمل برای انجام چیست. البته یادگیری ابزاری تنها به نتیجهی عمل کنونی بسنده نکرده، و ممکن است به صورت یک برنامهریزی روبهجلو دنبالهای از عملها را ارزیابی کند. از طرفی، برنامهریزی روبهجلو ممکن است تنها فرآیند برنامهریزیای نباشد که یادگیری ابزاری از آن استفاده میکند. ممکن است انسانها از برنامهریزی روبهوارو نیز به منظور ارزیابی توالی عملها بهره برند. با این وجود برنامهریزی روبهوارو کمتر تاکنون مورد توجه قرار گرفته است. پژوهشهای پیشین نشان دادند با وجود مستقل بودن یادگیری پاولفی و ابزاری، آنها با یکدیگر تعامل میکنند. در حقیقت بایاس پاولفی نزدیک شوندگی روی برنامهریزی روبهجلو تأثیر گذاشته و منجر به اتخاذ تصمیماتی میشود که ممکن است از نظر کنترلگر ابزاری بهینه نباشند. اما تأثیر یادگیری پاولفی روی برنامهریزی روبهوارو هنوز مطالعه نشده است. در این رساله، ما یک آزمایش مسیریابی طراحی کردیم که امکان برنامهریزیهای روبهجلو، روبهوارو، و دوسویه در آن فراهم است، و ایماهای پاولفی نزدیکشوندگی را نیز در نقشهها تعبیه نمودیم. تحلیل آماری دادههای جمعآوری شده از آزمایش نه تنها از وجود برنامهریزی روبهوارو حکایت میکنند، بلکه نشان میدهند که ایمای پاولفی نزدیکشوندگی بر روی سه برنامهریزی تأثیر میگذارد، هر چند که این تأثیر در برنامهریزی دوسویه بیشتر از روبهجلو، و در روبهجلو بیشتر از روبهوارو است. به منظور بررسی دقیقتر، تأثیر سه فاکتور دیگر شامل زمان تصمیمگیری، پیچیدگی آزمایش، و شدت نزدیکشوندگی ایمای پاولفی را روی برنامهریزیها نیز مورد بررسی قرار دادیم. همچنین در بستر یادگیری تقویتی، الگوریتم برنامهریزی دوسویه را تحت بایاس پاولفی گسترش دادیم. نتایج شبیهسازی الگوریتم با نتایج برآمده از آزمایش سازگار بوده و بیان میکنند که تأثیر بایاس پاولفی را میتوان به نوعی در قالب هرس درختان تصمیم مدلسازی نمود. تأثیر فاکتورها را نیز به صورت ظرفیت گسترش درختهای تصمیم در الگوریتم گسترش داده شده مدل کردیم.